AxonOps Review - An Operations Platform for Apache Cassandra
Note: Before we dive into this review of AxonOps and their offerings, it’s important to note that this blog post is part of a paid engagement in which I provided product feedback. AxonOps had no influence or say over the content of this post and did not have access to it prior to publishing.
In the ever-evolving landscape of data management, companies are constantly seeking solutions that can simplify the complexities of database operations. One such player in the market is AxonOps, a company that specializes in providing tooling for operating Apache Cassandra.
If you’ve followed my blog, or look back at the history, you’ll notice I’ve been in the Cassandra community for a decade and am passionate about what the project brings to the table. I’m also brutally honest about what it does not bring to the table - out of the box operational simplicity. To fill in the gaps, the community has seen the creation of many third party tools, both open source and commercial, that have attempted to address this. Open source tools are born out of a need to fill a gap and have done so quite successfully in many areas. For example, Medusa for backups and Reaper for managing repairs were both Spotify open source projects adopted by The Last Pickle (now DataStax). These tools have received a lot of love and I have a tremendous respect for the projects and the maintainers, who I’m lucky to have considered friends for many years.
Observability has been a mixed bag, with DataStax’s MCAC project making it a lot easier to integrate with Prometheus, although I’ve found it to cause performance issues on oversubscribed clusters with hundreds of tables when the agent collects too frequently. DataStax’s OpsCenter was previously available for open source Cassandra but has since been restricted to DataStax Enterprise customers only, leaving a large gap for folks looking for an out of the box solution for monitoring and management. The last time I tried the Prometheus JMX exporter it imposed significant overhead even on clusters that had very few tables.
Assembling several open source tools together, usually with custom tooling specific to one’s environment, is a very common practice. Unfortunately, for some teams this can be overwhelming. Having to evaluate multiple options can be time-consuming, especially when the database itself isn’t being operated by a team with seasoned Cassandra veterans and distributed systems experts on hand. This creates a following groups:
- Folks who want to run Cassandra themselves and are experts (or have the determination to be eventually)
- Folks who are OK with handing off this responsibility.
- Folks who want to run it themselves but aren’t experts.
On the extreme end of Group #1 are teams like Apple and Netflix, both of which I have had the privilege of being a part of, having some of the highest technically skilled people I’ve had the pleasure of working with. These teams build stuff by default, understand scale, automate as much as possible and contribute to open source. Many of these folks are core contributors to the project. Typically, the level of expertise required scales with the number of nodes / clusters and the number of issues the team has faced as that number has grown. I’ve seen several teams take a “we can’t keep doing this” stance leading to an investment in automation or training. Shameless plug for my services :)
For group #2, options like DataStax Astra and Instaclustr are popular options. Both companies have been around for a long time and also have seasoned Cassandra veterans and have contributed massively to the project over the years. Instaclustr seems to have branched out to a whole slew of database offerings beyond Cassandra.
That leaves us with group #3 - folks that want to run Cassandra themselves, aren’t experts, but need to be successful now. This is where AxonOps has found its niche, joining companies like Spunk or DataDog that provide hosted solutions but doing a bit more by taking on operations as well.
With a mission to streamline Cassandra management, AxonOps offers a suite of services that includes backups, repair, monitoring, log management, and security, ensuring that your database operates smoothly. Here we will explore the features that make AxonOps a comprehensive tool for Cassandra operations, while also discussing aspects where they can improve.
Monitoring and Logs
Effective monitoring and logging are key components of database management. Both can be a headache to set up, and either have particularly unique requirements in each environment. No matter what your stance on software choice, at the end of the day you need a comprehensive understanding of your hardware (see Brenden Gregg’s USE method) as well as detailed reporting on the behavior of your software. This means understanding throughput, latency and errors at every level. The resolution of your reporting matters a lot here too - some problems are difficult to track down if your metrics don’t get reported frequently enough. This issue has presented itself in both the Prometheus JMX collector and, in specific scenarios, with DataStax’s MCAC collector. I have observed that both of these collectors adversely affect Cassandra’s performance, making it challenging to rationalize frequent data collection. AxonOps sends metrics every 5 seconds, visible almost instantly, somehow while using less bandwidth, with very little impact, giving it a big advantage over what’s available in open source today.
Log management can often be a tedious and time-consuming task. There’s no shortage of options for managing logs. I’ve been very happy in the past with the ELK stack, and have used Splunk on several occasions. What AxonOps brings to the table is a solution tailored to Cassandra that integrates with the metrics view of the monitoring platform, making it trivial to centralize, analyze, and visualize log data generated by your Cassandra cluster. This streamlined approach to log management not only saves time but also facilitates troubleshooting and debugging, making it easier to maintain the health of your database.
One thing I really appreciate about AxonOp’s approach is the way the dashboards and logs are displayed together. When you narrow down the metrics to a smaller window, the logs are re-searched to only that time period. This is a nice detail that I really appreciate, as it makes it easier to correlate events with metrics.
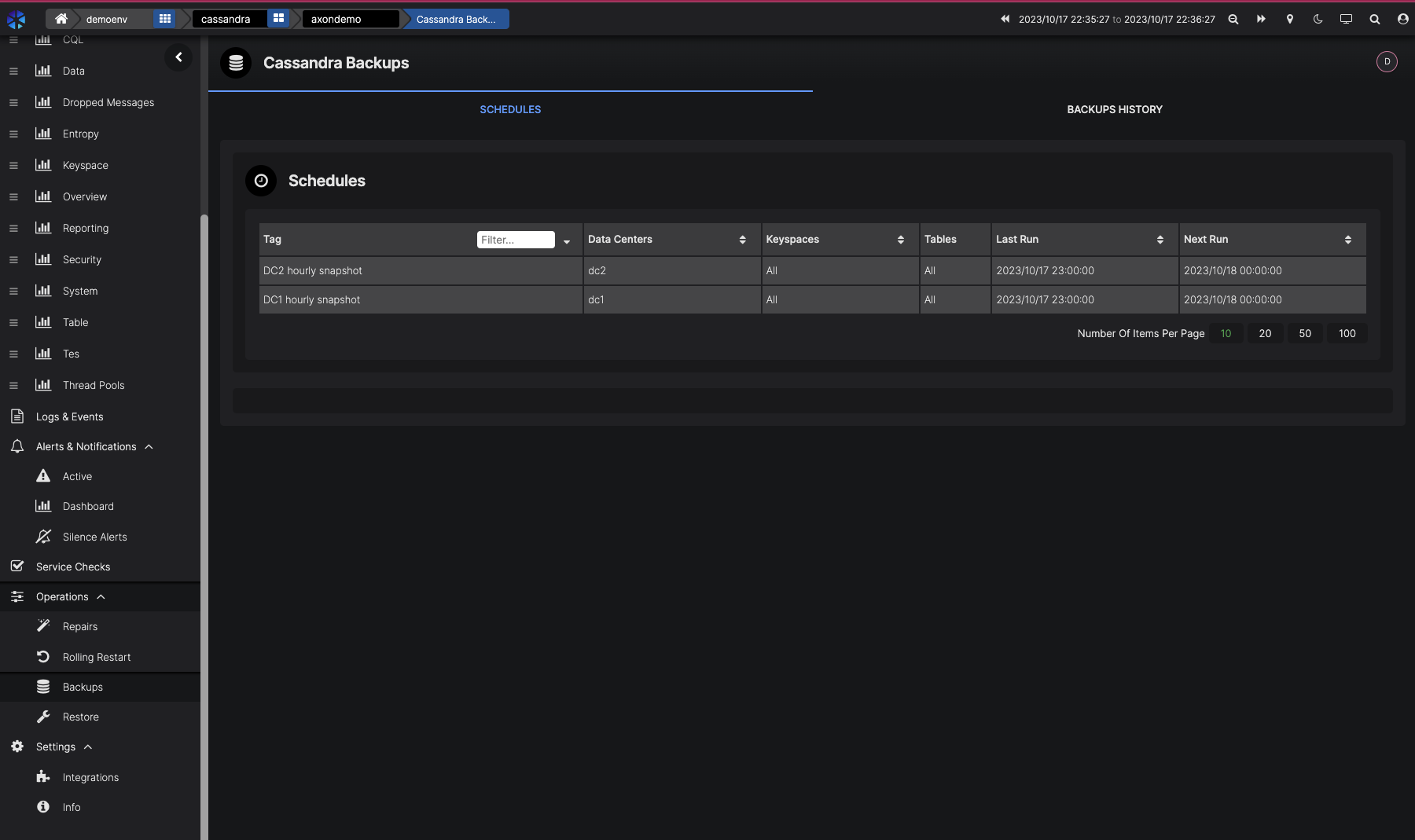
Backups
Some teams don’t bother with backups of their Cassandra clusters because they run in multiple DCs, but I think this is a bit reckless. There’s a number of ways you can lose data, and not a lot of ways to get it back without a backup. Backups with Medusa are fairly straightforward, but you’ll need to write some wrapper tooling to automate things like node replacement or cloning an entire cluster into a test environment if you want to run it at scale.
AxonOps excels in this aspect by providing reliable and automated backup solutions for your Cassandra cluster. The automated and manual backup system ensures that your data is consistently protected, and in the event of data loss or corruption, you can quickly restore it to its last known good state. This feature eliminates the stress and overhead of managing backups manually and enables you to focus on other critical tasks. Restoring can be done to a single node or an entire cluster.
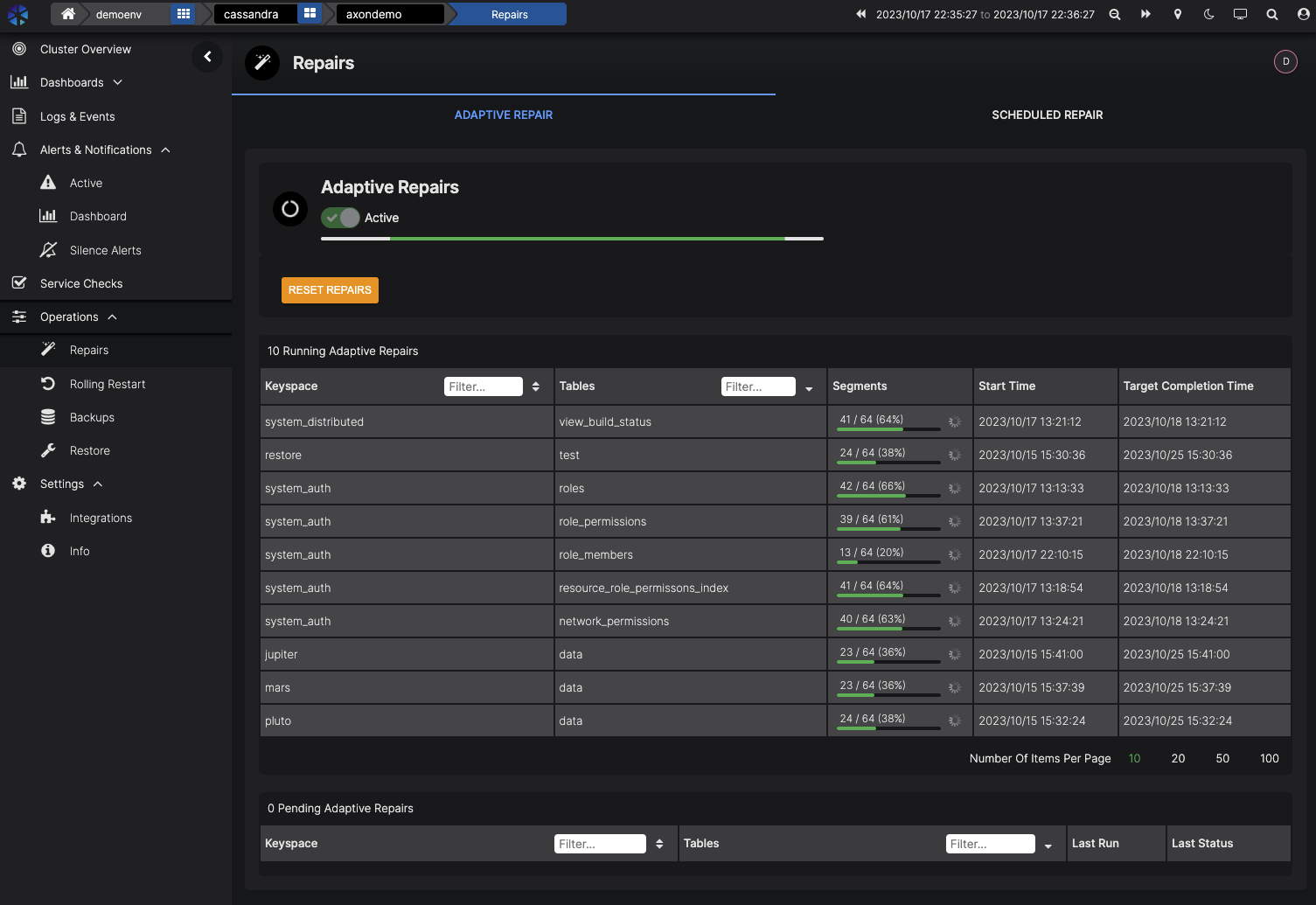
Adaptive Repair
Repair is a critical component of Cassandra operations, and AxonOps offers a unique approach to this process. Their adaptive repair system is designed to be as unobtrusive as possible, by only repairing when it’s safe to do so without impacting the cluster’s response time. This feature is especially useful for large clusters, where the repair process can be resource-intensive. I’ve worked on several clusters that have had performance impacted by OpsCenter’s somewhat simplistic repair service, and it’s nice to see a sophisticated approach to this problem. On a smaller scale, this might not seem significant, but when numerous teams are scheduling Spark jobs across multiple clusters, it can be a big help. In these types of environments it’s nice not to be concerned about having to police the cluster usage to prevent overlap of repair operations and processes that put a lot of strain on a cluster.
Security
One of the notable architectural decisions that I really appreciate is the decision to avoid requiring setting up networking ingres into your database cluster for the sake of executing operational tasks. The agent running on your nodes uses a persistent websocket communication to connect to the control plane which can then tell it to execute operations such as backups, repairs, rolling restarts, etc. This is little detail that helps make the platform an easier sell for security conscious teams.
External Integrations
One of the standout features of AxonOps that deserves special mention is its capacity for external integrations. AxonOps allows you to expose a PromQL (Prometheus Query Language) endpoint, making it brilliantly easy for users to pull AxonOps data directly into their own dashboards. This feature not only streamlines the process of aggregating data but also empowers users to tailor their monitoring and visualization experience to their exact needs. The ability to seamlessly integrate with your preferred tools and platforms is a testament to AxonOps’ commitment to providing flexibility and adaptability, which is a significant boon for users looking to customize their monitoring and reporting solutions.
What’s Missing: A Feature Wish List
While AxonOps offers an impressive range of tools and services, there are a couple notable gaps in their offering. The lack of profiling is something I would have really loved to see, both automated and manual, visualized as flame graphs. I’ve been a big advocate for flame graphs for years now, and have both written and spoken about them extensively. I relied on them frequently at Netflix to identify performance issues and have found them to be an invaluable tool for troubleshooting. It would be a valuable addition to AxonOps’ toolkit, and it’s something they might consider adding in the future to provide a more comprehensive solution for Cassandra operators. The async-profiler remains my favorite tool for this job. I’d love to see this be something that could get collected automatically if the resource usage goes over a specified limit.
AxonOps supports performing rolling restarts, but I’d like to see this extended to other arbitrary operations. For example, changing compression settings can yield massive improvements in performance for read heavy workloads, but requires all SSTables to be rewritten using nodetool upgradesstables -a to see the benefit. It would be great if this could be easily scheduled in the UI either as a one-off or on a routine.
The last item on my wish list that I’ll mention would be a recommendation / optimization engine. Between minimizing read ahead, optimizing compression, and a little GC tuning it’s possible to get a 10x improvement to throughput and latency for certain read heavy workloads. AxonOps has all the information they need to either provide this and eventually handle the tuning themselves. This would carry a lot of the benefits of a hosted solution without losing direct access to your cluster.
Conclusion
AxonOps is a remarkable company that simplifies the complexities of operating Apache Cassandra. With their focus on backups, monitoring, log management, and security, they provide almost everything you’d ever need for database operations.
In summary, if you’re seeking a reliable partner for understanding and operating Cassandra, AxonOps is a company worth considering. Their commitment to data safety, system performance, and security is commendable, and their expertise can help you navigate the intricacies of Cassandra operations with confidence. Keep an eye on their future developments as they strive to enhance their offering and further solidify their position as a leading player in the database operations field.
If you found this post helpful, please consider sharing to your network. I'm also available to help you be successful with your distributed systems! Please reach out if you're interested in working with me, and I'll be happy to schedule a free one-hour consultation.