RAMP Made Easy - Part 2
Introduction
In my previous post I introduced RAMP, a family of algorithms for managing atomicity on reads across distributed database partitions. The first algorithm discussed was RAMP-Fast, which is designed to perform with as few network round trips as possible at the cost of storing significant amounts of metadata. I suggest reading my first post if you aren’t familiar with RAMP as I’ll be referring to some of the concepts throughout this post.
One of the potential downsides of RAMP-Fast is that you might need to store a significant amount of metadata. If you’re issuing 1000 writes a second to a particular key with a lot of dependencies you’ll quickly find you’re storing hundreds of thousands of versions of an item with long lists of dependencies. While a good garbage collection process can mitigate this, we still might end up with the majority of our storage and memory being dedicated to storing metadata.
Here I’ll explore RAMP-Small, the second RAMP algorithm, which uses significantly less storage space but always requires exactly 2 network round trips to perform our read, as opposed to 1 round trip in the best case of RAMP-Fast.
RAMP-Small Writes
Writes with RAMP-Small are almost identical to RAMP-Fast, but do not need to include the dependency metadata. We’ll be using the unique timestamp to later identify which items were part of the same transaction.
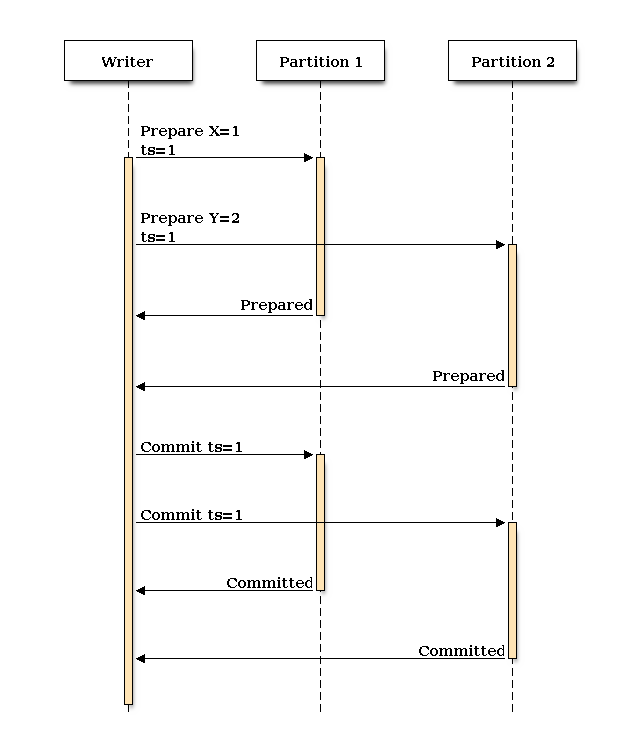
Reads
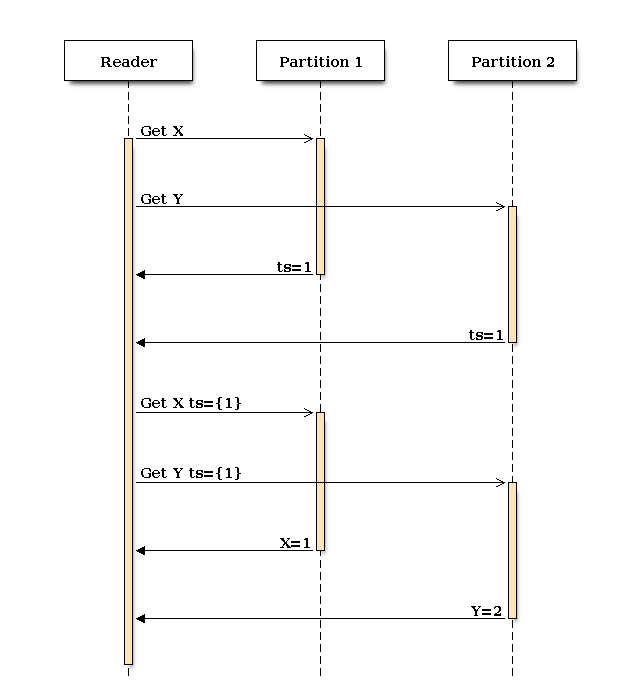
Let’s take a look at how normal reads are handled with RAMP-Small.
Unlike in RAMP-Fast, in our first Get() query, each partition is only required to return the timestamp for the highest committed timestamp for an item. What we get out of the first round is a set of timestamps.
In the second round, we send all the timestamps we have back with the items we’d like to retrieve. Just like with RAMP-Fast, the partition returns the value from the list of versions (including prepared but not committed) for the highest available timestamp included in the set of timestamps.
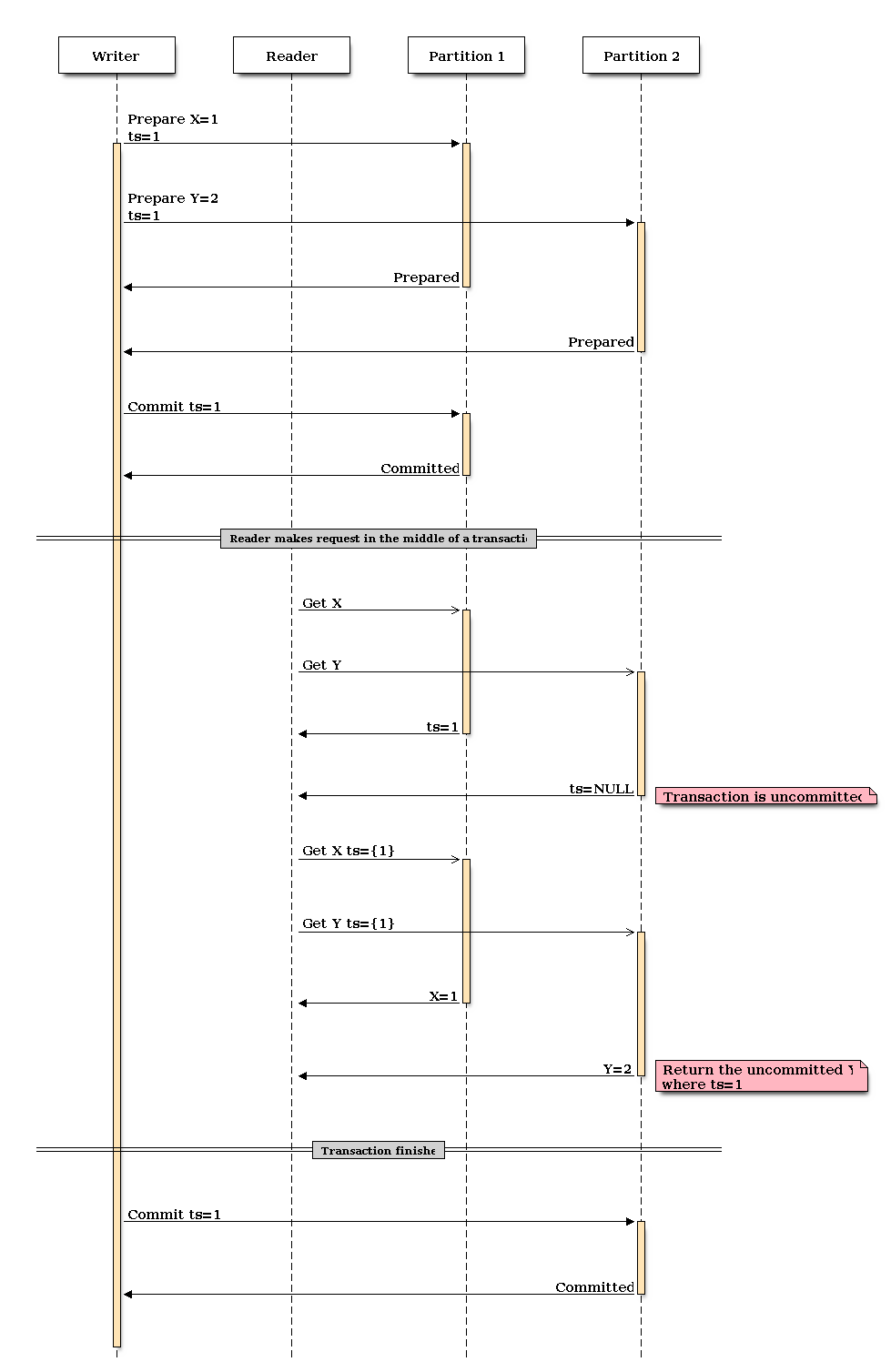
Let’s see how this works when we’re mixing readers and writers. To demonstrate how the algorithm works, we’ll commit only the first value, X=1, perform the read, then commit Y=2.
Conclusion
The reason why this algorithm works is subtle. When we issue our first read query, we get back a list of timestamps. This is the latest committed timestamp for each item. When we issue our second query, we include all the timestamps. We’re either going to get back the latest committed values that correspond to that timestamp or a value which has been prepared but not yet committed. This gives us similar behavior to RAMP-Fast. It works because in the RAMP world, timestamps must be unique. Rather than store the metadata which tells if we’re required to do a second trip, we always perform it. This is the space vs round trip tradeoff.
In the next post, we’ll take a look at RAMP-Hybrid, which utilizes bloom filters to achieve a nice balance between the performance of RAMP-Fast and the cheap storage cost of RAMP-Small.
If you found this post helpful, please consider sharing to your network. I'm also available to help you be successful with your distributed systems! Please reach out if you're interested in working with me, and I'll be happy to schedule a free one-hour consultation.