RAMP Made Easy
Introduction
In this post I’ll introduce RAMP, a family of algorithms for performing atomic reads across partitions when working with distributed databases. The original paper, Scalable Atomic Visibility with RAMP Transactions, was written by Peter Bailis, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein and Ion Stoica, of UC Berkeley and University of Sydney. Peter has graciously reviewed this blog post to ensure its accuracy. As part of the overview, I’ll explain the RAMP-Fast algorithm, the first of 3 algorithms covered in the paper. RAMP-Small and RAMP-Hybrid will be covered in follow up posts. First, let’s take a look at a few properties of database systems.
A Single Database Server
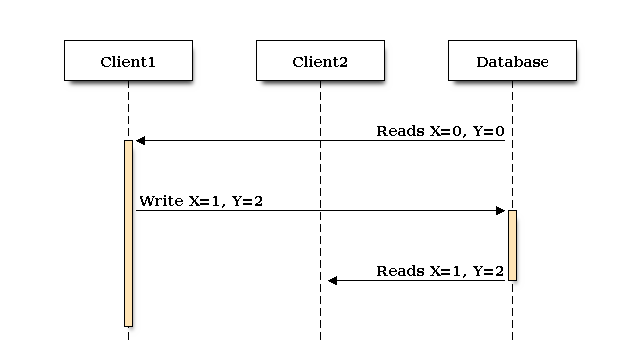
It’s easy to take for granted certain behavior when working with a database on a single server. A task like updating a secondary index typically occurs synchronously with the change to the underlying data. We expect both atomicity and consistency when working with data & indexes. It would be surprising to get back the result of a query and realize the index data didn’t match our source record. This doesn’t just apply to indexes, we can usually update two rows and to our clients performing requests they’ll appear to change together, atomically. In the following example you can see how Client1 and Client2 perform reads while writes are occurring and never get partially written values, the writes occur atomically:
Distributed Databases
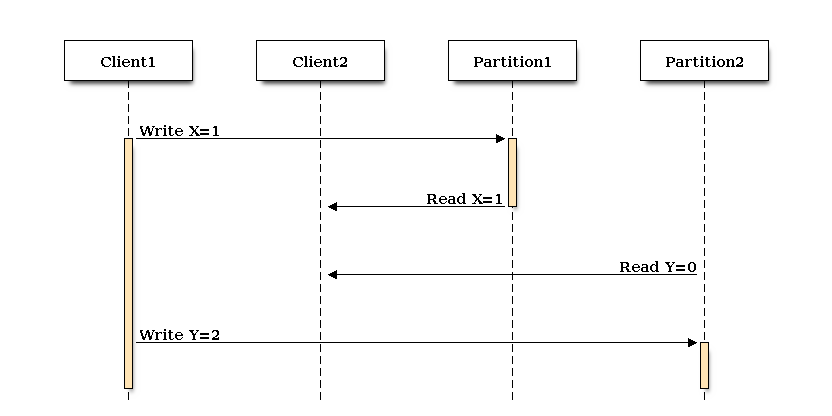
Distributed databases, on the other hand, are a little bit more complex. We typically relax the consistency constraints on our data with the goal of achieving higher availability and scalability. The cost of acquiring locks across multiple servers by issuing many round trips across a network can be fairly unpredictable when under contention. If we’re updating 2 values on 2 different servers (partitions), like in our index example, it’s likely that we’ll read those values in an intermediate stage. In this example we’re able to read data from 2 partitions on 2 servers, and get back X=1, Y=0.
On the plus side most applications don’t actually need perfect locking all the time. We’re typically willing to make the tradeoff of some inconsistency for scale and high availability across many servers or data centers. If maintaining our indexes across machines comes at a significant cost, most of the time we’ll opt to skip it entirely and just write to the index and source data asynchronously.
There are, of course, plenty of cases where we’d like to read and write to multiple partitions and never get the intermediate result of one value being set with the other not. Our secondary indexes being totally inaccurate may not be an acceptable tradeoff.
What if we could figure out a compromise - a way to manage our distributed data at a relatively minor cost? If we don’t need ACID transactions but would still like to read and write to multiple keys in atomic way - RAMP may be the right solution.
The Setup
We’re going to be reading and writing data to 2 partitions on 2 servers. The original values will be X=0 and Y=0. Our distributed transaction will atomically change the values. To a client, the values will appear to change instantly to X=1 and Y=2, we will never get X=0, Y=2, or X=1, Y=0 like we did in the previous example. We will always see either all the transactions or none of them.
RAMP-Fast Writes
The first algorithm covered in the original paper and here is RAMP-Fast. The goal of RAMP-Fast is to provide an answer in as few network round trips as possible on reads at the cost of storing additional metadata (abbreviated md in the example below).
Each server maintains a version history for each item. For each version we have something like the following tuple:
(item, value, timestamp, metadata)
Metadata will be a list of dependencies. If a transaction involves the keys (X,Y), then the metadata for transaction X will simply be {Y}. Likewise, the dependencies for Y will be {X}.
Each write includes a unique timestamp which is later referenced in the commit process. I’ll use an integer here to keep things simple but we might use a UUID version 1 (TimeUUID) in our database to ensure uniqueness.
Let’s look at how our writer works without having to worry about concurrent reads. After our transaction is committed, I’ll show how reads are handled.
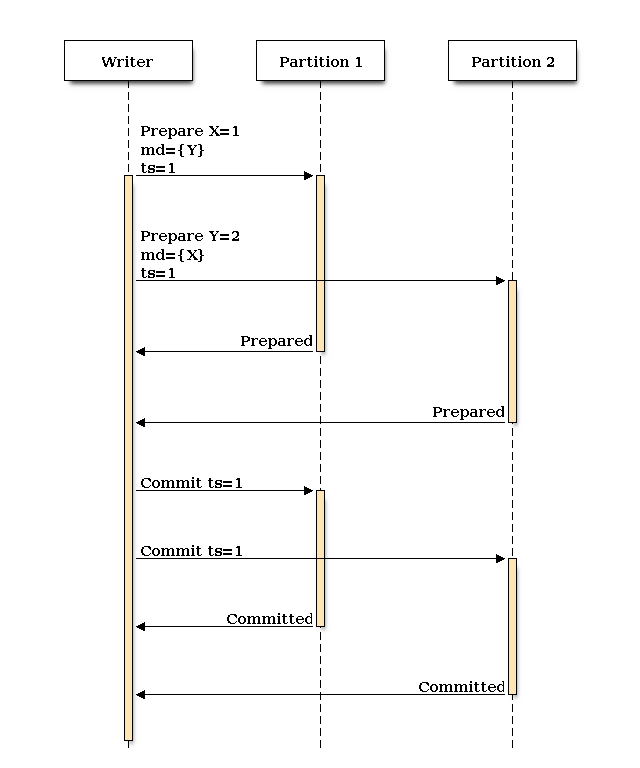
It’s important to note that RAMP uses a 2 phase commit process. The first step, prepare, sends the item, value, timestamp, and metadata to each database partition. We block, waiting on a result from all partitions before proceeding. This phase can occur concurrently with other clients, we are not using expensive exclusive locks for this operation.
The second phase, the commit, tells each partition that the prepare has executed successfully on every server and we can now use our prepared value as the new current value for the given item. Like the first phase, this occurs concurrently with other clients to minimize performance impact.
In the example above, we can prepare both the X and Y values with timestamp 1, then block to get the result from both. Assuming both values are prepared OK, we can issue a commit to each server. How is our data read?
RAMP-Fast Reads
RAMP-Fast allows us to perform a read with 1 round trip per partition under optimal conditions and 2 round trips under the worst case. Our first request returns the highest commited value, timestamp, and metadata (dependency list) for each item. If an item has a dependency on another item (X on Y, for example), then the dependency’s timestamp must be at least that of the item’s timestamp. To put it another way, if X and Y were part of the same tranaction, we don’t want to get back an old version of Y.
Here’s what the request looks like under ideal conditions, where we get back the latest committed verion of both X and Y:
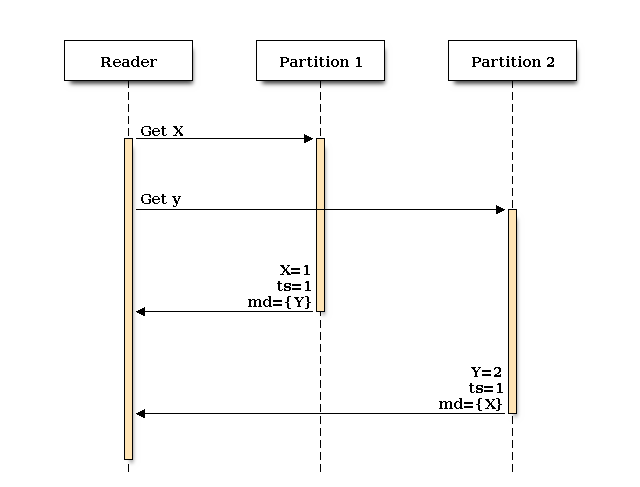
We get back X=1, ts=1, md={Y} from partition 1 and Y=2, ts=1, md={X} from partition 2. To calculate if we have satisfied at atomic read, we can examine our results. X has a dependency on Y (and vice versa). X.ts >= Y.ts and Y.ts >= X.ts, so we’ve satisfied our dependencies and we can use the values X=1, Y=2.
It shouldn’t be a surprise that reading 2 committed values returns the right answer. What happens if we issue a read when only 1 item has been committed? Let’s take a look at our timeline.
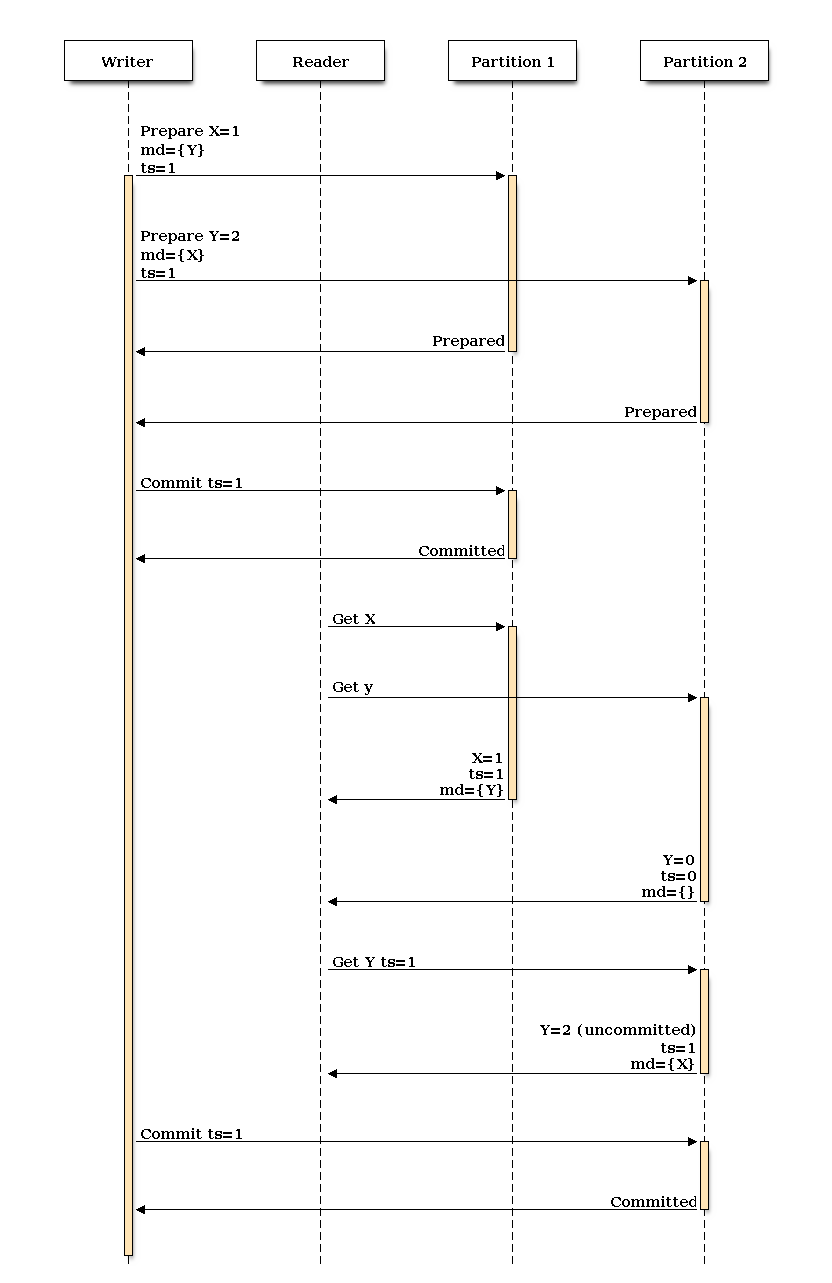
In this scenario, we’ve issued a read after X has been committed but before Y has. Our returned data looks like this:
(X=1, ts=1, md={Y})
(Y=0, ts=0, md={})
X has a dependency on Y. When we compare the timestamps, we see that we have an old version of Y (ts=0) that doesn’t meet our timestamp requirement. We’ve fetched 2 values at different states in the transaction. We issue a second call to fetch Y at its (potentially) uncommitted state where ts=1. We know that Y=2 must have been prepared on Partition 2 because we’ve already seen a committed version of X at ts=1, and for a X to have been committed, we had to have blocked on all prepare calls.
We can see here that we get back correct results even if we issue a read when a transaction is only partially committed.
It’s important to note that the only goal here to to achieve atomic reads of multiple items. We have not added serializability to our system. This is not a solution for when perfect isolation is required.
Conclusion
At this point, you should have a decent understanding of the complexity of keeping data in sync across partitioned, distributed databases. The RAMP family of algorithms are designed to provide atomic reads across partitions without adding significant overhead - in a non blocking way. Our reads are guaranteed to complete with a maximum of 2 round trips, and operations from multiple clients can occur concurrently.
The RAMP family is not designed to provide ACID guarantees - it’s for situations where atomic reads are good enough. Concurrent writes will typically be handled with last write wins or CRDTs.
The RAMP-Fast algorithm is designed for maximum performance at the tradeoff of tracking extra metadata. What do we do if the cost of storing this metadata is too high? In the next post, I’ll cover RAMP-Small, which to perform more round trips on average but keep track of potentially a lot less metadata.
Update: the RAMP-Small post is up!
Feel free to reach out to me on Twitter with any questions or comments!
If you found this post helpful, please consider sharing to your network. I'm also available to help you be successful with your distributed systems! Please reach out if you're interested in working with me, and I'll be happy to schedule a free one-hour consultation.