Spark Streaming With Python and Kafka
Last week I wrote about using PySpark with Cassandra, showing how we can take tables out of Cassandra and easily apply arbitrary filters using DataFrames. This is great if you want to do exploratory work or operate on large datasets. What if you’re interested in ingesting lots of data and getting near real time feedback into your application? Enter Spark Streaming.
Spark streaming is the process of ingesting and operating on data in microbatches, which are generated repeatedly on a fixed window of time. You can visualize it like this:
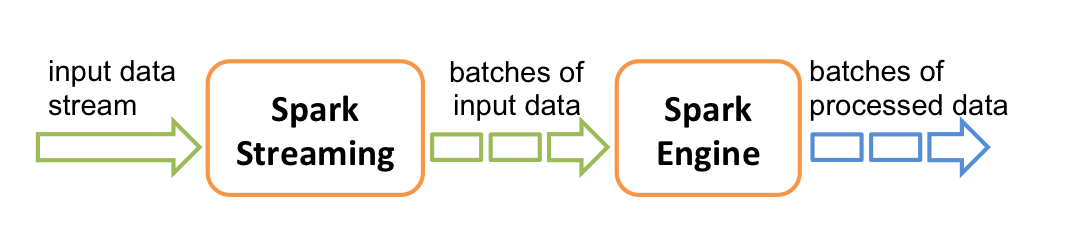
To store both our raw and aggregated data I’ll be using Cassandra. It’s the right fit for application that require high availability.
Why would you use it?
If you want semi-real time analysis of your data that is not millisecond sensitive. If you need the fastest possible response time to an incoming stream of information, (high frequency trading is a good example), you’ll likely be more interested in Apache Storm. Most of the stuff I’ve worked on doesn’t require absolute minimum latency so we’re OK to use microbatches. A nice part about using Spark for streaming is that you get to use all the other great tooling in the Spark ecosystem like batching and machine learning.
Requirements
I’ll assume you have Kafka set up already, and it’s running on localhost, as well as Spark Standalone. We need to use at least Spark 1.3 since previous versions do not support streaming with Python. To set up Kafka, follow the quickstart. Follow my previous post to set up spark standalone. Come back when you’re up and running. I’m using Cassandra to store all my aggregated data, so if you’re going to run the code I’ve provided, you’ll need that as well. I’ve got Kafka set up to create topics automatically for convenience, if you don’t set that up you’ll want to create a topic called “pageviews”.
Let’s get our hands dirty.
We’re going to be examing the spark streaming job that’s part of my project KillrAnalytics. To keep a reference to this post I’ve created a tag in the repo called intro_streaming_python.
We’ll need a way to push sample data into our Kafka topic, cleverly named fill_kafka.py. We’re going to JSON encode some very trivial data, for now hardcoded to a specific site. In the future this app will handle many sites (similar to Google Analytics) but for now we’ll only do 1 since we’re just learning.
Let’s first import everything we need. This means the pyspark streaming module, pyspark.streaming, and if you’re saving to Cassandra, the pyspark_cassandra.streaming module. Since we’re decoding JSON we’ll also need Python’s JSON module.
import pyspark_cassandra
import pyspark_cassandra.streaming
from pyspark_cassandra import CassandraSparkContext
from pyspark.sql import SQLContext
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
from uuid import uuid1
import json
Next we create a SparkConf, a streaming context, and our Kafka Stream. When we create the stream we need to pass our zookeeper address, a name, and the topic we’re going to consume from.
# set up our contexts
sc = CassandraSparkContext(conf=conf)
sql = SQLContext(sc)
stream = StreamingContext(sc, 1) # 1 second window
kafka_stream = KafkaUtils.createStream(stream, \
"localhost:2181", \
"raw-event-streaming-consumer",
{"pageviews":1})
The operations that we do on the kafka_stream will look to us like we’re just performing transformations on a single RDD, but it’s doing much more than that. We don’t have to worry about explicitly doing some while loop and managing failures & retries, Spark does that for us. We can treat kafka_stream like a regular RDD (mostly). Here’s what the incoming data looks like:
(None, u'{"site_id": "02559c4f-ec20-4579-b2ca-72922a90d0df", "page": "/something.css"}')
Let’s extract the data out of the 2 item tuple and decode it into something we can work with - a Python dictionary.
parsed = kafka_stream.map(lambda (k, v): json.loads(v))
Next we’re going to aggregate the pageviews to a given site. To keep the complexity to a minimum we’re not yet going to split the data out by page.
The first thing we’ll do is map site_id to 1, then count the number of 1s (via reduceByKey). We’ll then turn the whole thing into a friendly dictionary with site_id and a page view count.
summed = parsed.map(lambda event: (event['site_id'], 1)).\
reduceByKey(lambda x,y: x + y).\
map(lambda x: {"site_id": x[0], "ts": str(uuid1()), "pageviews": x[1]})
Let’s save the results to Cassandra. What I love about this is if your RDD of dictionaries matches your Cassandra table structure you can just issue the following command:
summed.saveToCassandra("killranalytics", "real_time_data")
We can now tell Spark we want to start the stream.
stream.start()
stream.awaitTermination()
Submit your streaming job
Time to start up our script that pushes fake data into our Kafka topic:
python bin/fill_kafka.py
To make testing easier, I’ve set up a little bash script called sub which I use to execute my job. As of this writing I wasn’t able to get the --packages option to work correctly so I’ll continue to use this:
VERSION=0.1.4
spark-submit --packages org.apache.spark:spark-streaming-kafka_2.10:1.3.1 \
--jars /Users/jhaddad/dev/pyspark-cassandra/target/pyspark_cassandra-${VERSION}.jar \
--driver-class-path /Users/jhaddad/dev/pyspark-cassandra/target/pyspark_cassandra-${VERSION}.jar \
--py-files /Users/jhaddad/dev/pyspark-cassandra/target/pyspark_cassandra-${VERSION}-py2.7.egg \
--conf spark.cassandra.connection.host=127.0.0.1 \
--master spark://127.0.0.1:7077 \
$1
To submit my job I do the following:
./sub killranalytics/spark/raw_event_stream_processing.py
You can watch the output of the Spark streaming job to make sure everything runs ok. Assuming it does, you can check your table in Cassandra to see the aggregated information. Open a CQL shell:
cqlsh -k killranalytics
And check your table:
cqlsh:killranalytics> select * from real_time_data ;
site_id | ts | pageviews
--------------------------------------+--------------------------------------+-----------
02559c4f-ec20-4579-b2ca-72922a90d0df | e7c6d647-f4ed-11e4-a75d-74d4358a0878 | 3
02559c4f-ec20-4579-b2ca-72922a90d0df | 3122f007-f4ee-11e4-99e4-74d4358a0878 | 5
02559c4f-ec20-4579-b2ca-72922a90d0df | 31b3c8c2-f4ee-11e4-86c7-74d4358a0878 | 5
....
I ran this job for a little while, so I’ve truncated the results.
To see the code in it’s entirety you can reference the Spark streaming job.
What’s next
At this point you should be able to create simple Spark streaming jobs, aggregating and processing data as it comes into the system. It’s possible to do quite a bit with Spark Streaming, I’ll be coming back to this topic in several follow up posts.
If you found this post helpful, please consider sharing to your network. I'm also available to help you be successful with your distributed systems! Please reach out if you're interested in working with me, and I'll be happy to schedule a free one-hour consultation.