Python for Programmers
When I started learning Python, there’s a few things I wish I had known about. It took a while to learn them all. This is my attempt to compile the highlights into a single post. This post is targeted towards experienced programmers just getting started with Python who want to skip the first few months of researching the Python equivalents of tools they are already used to. The sections on package management and standard tools will be helpful to beginners as well.
My experience is mainly with Python 2.7, but many of the same tools should work with newer versions.
If you have never used Python before, I strongly suggest reading the Python introduction, as you’ll need to know basic syntax and types.
Package Management
One great part of the Python universe is the sheer number of third party packages. It’s also very easy to manage these packages. By convention, a project lists the packages it needs in a requirements.txt file. You’ll see 1 package per line, generally including a version. Here’s a sample from this blog, which uses Pelican:
pelican==3.3
Markdown
pelican-extended-sitemap==1.0.0
One drawback to Python’s packages is that by default they are globally installed. We’re going to use a tool that lets us have an environment for each project call virtualenv. We’ll also set up a more advanced package management tool called pip that works well with virtualenv.
First, we should install pip. Most python installations already have easy_install (the default Python package manager), so we simply easy_install pip. This should be one of the last times you’ll use easy_install. If you don’t have easy_install already, on linux it seems to be available in the python-setuptools package.
If you’re using Python >= 3.3, Virtualenv is part of the standard library, so installing it is unnecessary.
Next up, you’ll want to install virtualenv and virtualenvwrapper. Virtualenv lets you create an isolated environment for each project. Especially useful when you use different versions of packages in different projects. Virtualenv wrapper provides a few nice scripts to make things a little easier.
sudo pip install virtualenvwrapper
When virtualenvwrapper is installed, it lists virtualenv as a dependency, so it’s automatically installed.
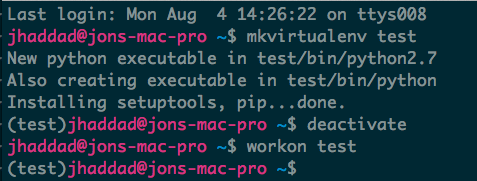
Open a new shell, and type mkvirtualenv test. If you open another shell, you won’t be in the virtualenv, and can activate it using workon test. If you’re done, you can simply deactivate.
IPython
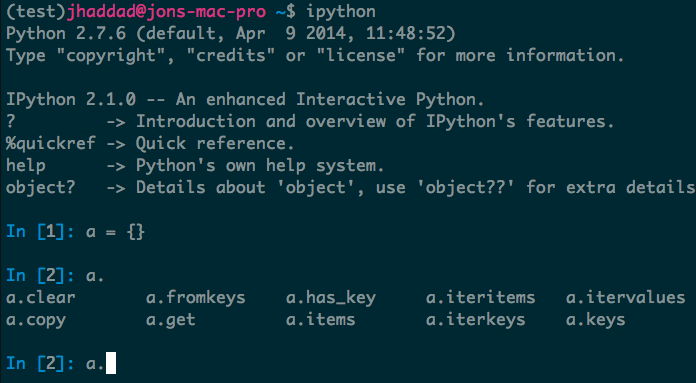
IPython is an alternative to the standard Python REPL that allows for auto complete, quick access to docs, and a slew of other features that really should have been in the standard REPL.
Simply pip install ipython while you’re in a virtual environment. Start it on the command line with ipython.
Also nice is the “notebook” feature, which requires additional components. After installing, you’ll be able to ipython notebook and get a nice web UI where you can build out notebooks. It’s very popular in scientific computing.
Testing
I recommend getting nose or py.test. I’ve used nose mostly. Getting started with either is roughly the same amount of work. I’ll give details on nose.
Here’s a ridiculously contrived example of a test in nose. Anything function that starts with test_ in a file that starts with test_ will be called:
def test_equality():
assert True == False
As expected, our test will fail when we tell nose to run:
(test)jhaddad@jons-mac-pro ~VIRTUAL_ENV/src$ nosetests
F
======================================================================
FAIL: test_nose_example.test_equality
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jhaddad/.virtualenvs/test/lib/python2.7/site-packages/nose/case.py", line 197, in runTest
self.test(*self.arg)
File "/Users/jhaddad/.virtualenvs/test/src/test_nose_example.py", line 3, in test_equality
assert True == False
AssertionError
----------------------------------------------------------------------
There’s also some convenience methods in nose.tools:
from nose.tools import assert_true
def test_equality():
assert_true(False)
If you’re more comfortable using an approach similar to JUnit, that’s fine too:
from nose.tools import assert_true
from unittest import TestCase
class ExampleTest(TestCase):
def setUp(self): # setUp & tearDown are both available
self.blah = False
def test_blah(self):
self.assertTrue(self.blah)
Running the tests:
(test)jhaddad@jons-mac-pro ~VIRTUAL_ENV/src$ nosetests
F
======================================================================
FAIL: test_blah (test_nose_example.ExampleTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jhaddad/.virtualenvs/test/src/test_nose_example.py", line 11, in test_blah
self.assertTrue(self.blah)
AssertionError: False is not true
----------------------------------------------------------------------
Ran 1 test in 0.003s
FAILED (failures=1)
The excellent Mock library is included with Python 3, but if you’re using Python 2 it’s available through pypi. Here’s a test that makes a remote call, but that call takes 10 seconds. The example is obviously contrived. We use a mock to return sample data rather than actually make the call.
import mock
from mock import patch
from time import sleep
class Sweetness(object):
def slow_remote_call(self):
sleep(10)
return "some_data" # lets pretend we get this back from our remote api call
def test_long_call():
s = Sweetness()
result = s.slow_remote_call()
assert result == "some_data"
Of course, our tests take forever.
(test)jhaddad@jons-mac-pro ~VIRTUAL_ENV/src$ nosetests test_mock.py
Ran 1 test in 10.001s
OK
Ack, too slow! So we ask ourselves, what are we testing? Do we need to test that the remote call works, or do we need to test what we do with the data once we get it back? In most cases, it’s the latter. Let’s mock away that silly remote call:
import mock
from mock import patch
from time import sleep
class Sweetness(object):
def slow_remote_call(self):
sleep(10)
return "some_data" # lets pretend we get this back from our remote api call
def test_long_call():
s = Sweetness()
with patch.object(s, "slow_remote_call", return_value="some_data"):
result = s.slow_remote_call()
assert result == "some_data"
Alright, let’s try again:
(test)jhaddad@jons-mac-pro ~VIRTUAL_ENV/src$ nosetests test_mock.py
.
----------------------------------------------------------------------
Ran 1 test in 0.001s
OK
Much better. Keep in mind this example is ridiculously simplified. Personally, I only mock calls to remote systems, not to my database.
nose-progressive is a great module that improves the output of nose to show you errors as they happen rather than hide them till the end. This is nice if you’ve got tests that take a while. pip install nose-progressive and add --with-progressive to your nosetests command.
Debugging
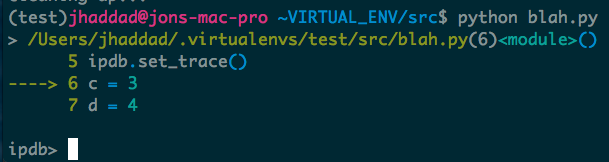
iPDB is an excellent tool that I’ve used to figure out some weird bugs. pip install ipdb, then add the line import ipdb; ipdb.set_trace() somewhere in your code, and you get a nice interactive prompt in your running program. It’s each to step through a program one line at a time and inspect variables.
There’s a nice tracing module built into python that’s helped me figure out exactly what’s going on. Here’s a trivial python program:
a = 1
b = 2
a = b
And our trace of that program:
(test)jhaddad@jons-mac-pro ~VIRTUAL_ENV/src$ python -m trace --trace tracing.py 1 ↵
--- modulename: tracing, funcname: <module>
tracing.py(1): a = 1
tracing.py(2): b = 2
tracing.py(3): a = b
--- modulename: trace, funcname: _unsettrace
trace.py(80): sys.settrace(None)
This is very useful when you’re trying to figure out the internals of some other program. If you’ve used strace before, this works similarly.
I’ve used pycallgraph to track down performance issues on several occasions. It builds a nice graph of your call times and call count.
Lastly, objgraph is very useful for hunting down memory leaks. Here’s a great blog post on how to use it to hunt down memory leaks.
Gevent
Gevent is a great library that wraps Greenlets, which add the ability to do async calls in Python. Yes, it’s awesome. My favorite feature is the Pool, which abstracts away the async part and gives us something easier to work with, an async map():
from gevent import monkey
monkey.patch_all()
from time import sleep, time
def fetch_url(url):
print "Fetching %s" % url
sleep(10)
print "Done fetching %s" % url
from gevent.pool import Pool
urls = ["http://test.com", "http://bacon.com", "http://eggs.com"]
p = Pool(10)
start = time()
p.map(fetch_url, urls)
print time() - start
It’s important to note the gevent monkey patching at the top, without it, this won’t work correctly. If we called fetch_url 3 times in a row with Python we’d normally expect this to take 30 seconds. With gevent:
(test)jhaddad@jons-mac-pro ~VIRTUAL_ENV/src$ python g.py
Fetching http://test.com
Fetching http://bacon.com
Fetching http://eggs.com
Done fetching http://test.com
Done fetching http://bacon.com
Done fetching http://eggs.com
10.001791954
Useful if you’ve got lots of database calls or fetching from remote URLs. I’m not a big fan of callbacks so this abstraction works well for me.
Conclusion
Alright, if you’ve made it this far, there’s a good chance you’ve learned something new. These are the tools that made the biggest impact on me over the last few years. It took a while to track them all down, so hopefully this reduces the effort other people have to make to get used to this excellent language.
If you found this post helpful, please consider sharing to your network. I'm also available to help you be successful with your distributed systems! Please reach out if you're interested in working with me, and I'll be happy to schedule a free one-hour consultation.